Zili Lab
Investigating how frustrating UX features influence user behavior in messaging apps
My team: UX Research Group from Zili Lab in UCLA School of Psychology
Members: Principal investigator: Dr. Zili Liu; Project director: Dr. Lucy Cui; Research Assistants: Sharon Zhao, Brandon Day, Maleeha Zaman, Jonathan Keung, Khoa Le, Ashley Wang, Chelsea Wan
My role: UX Researcher, UX Designer
Timeline: 2023.1 – 2024.6
We are surrounded by an overwhelming amount of information on a regular basis. Good UX designs help us better interact with the world and satisfy our goals. However, the effects of bad UX designs are seldom investigated. We hope to better understand how people select, use and interpret different types of information in a context of frustrating product experience (with a simplified messaging app). We also wish to utilize commonly used industry UX research tools (usability testing, qualitative coding, bootstrapping, etc) to validate their effectiveness.
Research questions:
What kinds of UX design decisions affect commonly used chat apps the most?
What kinds of UX features frustrate users most?
What kinds of UX research strategies are most effective in interpreting bad user responses?
Are there any external factors (personality, relationship to researcher, research setting) that affect user feedback?

Background
Define
In this initial stage, our team aimed to decide the type of the product that we will be using to run the study. We wanted to select a product type that is relatively straight-forward to understand and familiar to our target users — undergraduate students. We also went through multiple brainstorming sessions to narrow down the types of frustrating features we will be testing.
1. Selecting product type: Why testing in a messaging app?
Me and other 4 research assistants created a brainstorm chart for product type selection. Since our test will be conducted with college students, we proposed 3 types of apps that are used most frequently among target users. The product types were evaluated based on the their use frequency, design complexity, test complexity, and possibility for frustration. We decided to run the research project with a messaging app because among all the metrics, a messaging app is the product type that students interact with most frequently and has the most potential to be developed with the most frustrating features in a relatively shorter time span.

2. Selecting frustrating features: Which features to test?
After a literature review on features that people are commonly disappointed at, our team brainstormed the types of features that we can manipulate in our messaging app and the scenarios for stimulating frustration. These features were implemented to a messaging app that has basic functions.
Wireframe & Prototype
Once we have all features ready for prototyping, I created a first-draft prototype to use in the piloting period. The prototype has 4 main features for stimulating frustration among users.
Frames

Start a direct message

Start a group chat

Leave a chat

Snooze a chat
Prototype
User flows
At last, based on the literature search and prototype development, we have created 6 frustrating features that can be implemented in common user scenarios.
Our main goals during the piloting period were:
Investigate order effects and learning effects to better organize task orders before actually collecting data
Look for a way to operationalize user facial expressions, user flows, and qualitative responses
Our target collection results are:
Get 100+ responses to analyze and interpret
Make 1 iteration during the piloting session
Pilot Study
Part 1. Thematic Analysis
Rationale: According to how users respond to different tasks, our team came up with 5 big categories of responses based on the content that they verbalized during each session. This helped us get a sense of which parts of the app users typically pay attention to, so that we could orient our questions towards this direction in official data collection. We also grouped responses according to affection level to see how “frustrated” users appear to be when completing the tasks we have assigned to them. Based on their affective responses, we created a table to formally code each user’s behavior qualitatively.
Process:
Based on user behaviors:


With the qualitative coding guidelines we have created, all sessions were coded in the format of the following example.
The primary objective of this analysis was to measure the agreement between raters on specific user behaviors and emotions during the sessions. The process involved several key steps:
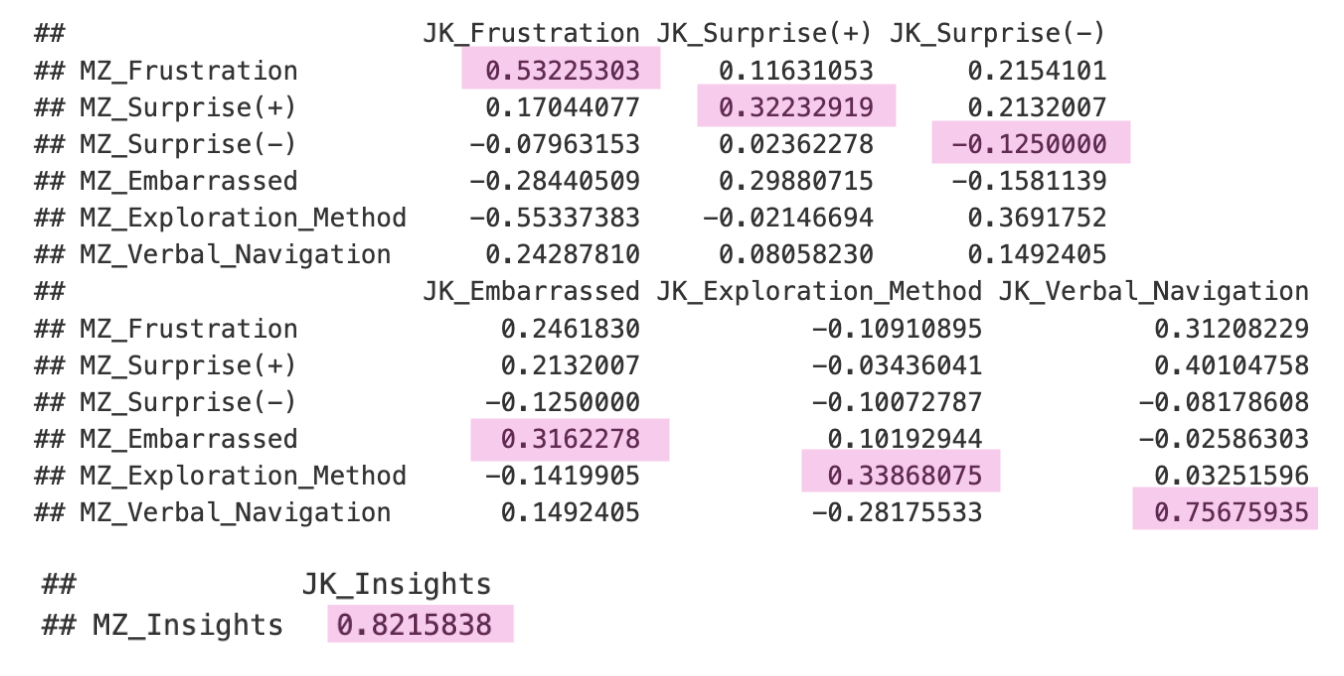
1. Correlation Analysis: We utilized Pearson’s Correlation to assess the strength and direction of the linear relationship between the raters’ scores across all sessions. This method helped us quantify how consistently both raters coded continuous variables like user emotions and actions. As a sanity check, we also applied Spearman’s Correlation for ordinal variables, confirming that the results aligned with those from Pearson’s analysis.

Pearson’s correlation
2. Interrater Reliability: To further evaluate the consistency between raters, we measured Interrater Reliability (IRR) using Cohen’s Kappa and Percentage Agreement. Cohen’s Kappa accounts for the possibility of agreement occurring by chance, offering a more rigorous assessment of consistency for both continuous and binary-coded variables.
The results revealed moderate to substantial agreement for certain variables, such as frustration, with the highest agreement observed in sessions conducted by Maleeha (Cohen’s Kappa = 0.75). However, variables like Surprise (+) and Surprise (-) presented challenges, with correlation coefficients close to 0 and Kappa values indicating only fair or slight agreement. This led to uncertainty in interpreting these binary variables and prompted a review of our coding guidelines.
Part 2. Quantitative Analysis
We conducted correlation studies that provides insights into how these variables relate to each other:
Quit Rate (quit_count): The number of times users quit the experience.
Openness to Experience: A personality trait that might affect how users engage with a task.
Total Confusion Count (tot_confusion_cnt): The number of instances where users exhibited confusion.
The correlation analysis aimed to uncover relationships between these metrics. For example, higher "quit rates" may correlate with increased confusion, indicating that when users are confused, they are more likely to abandon the task. Similarly, understanding how "openness to experience" influences these outcomes can provide valuable insights into user behavior.
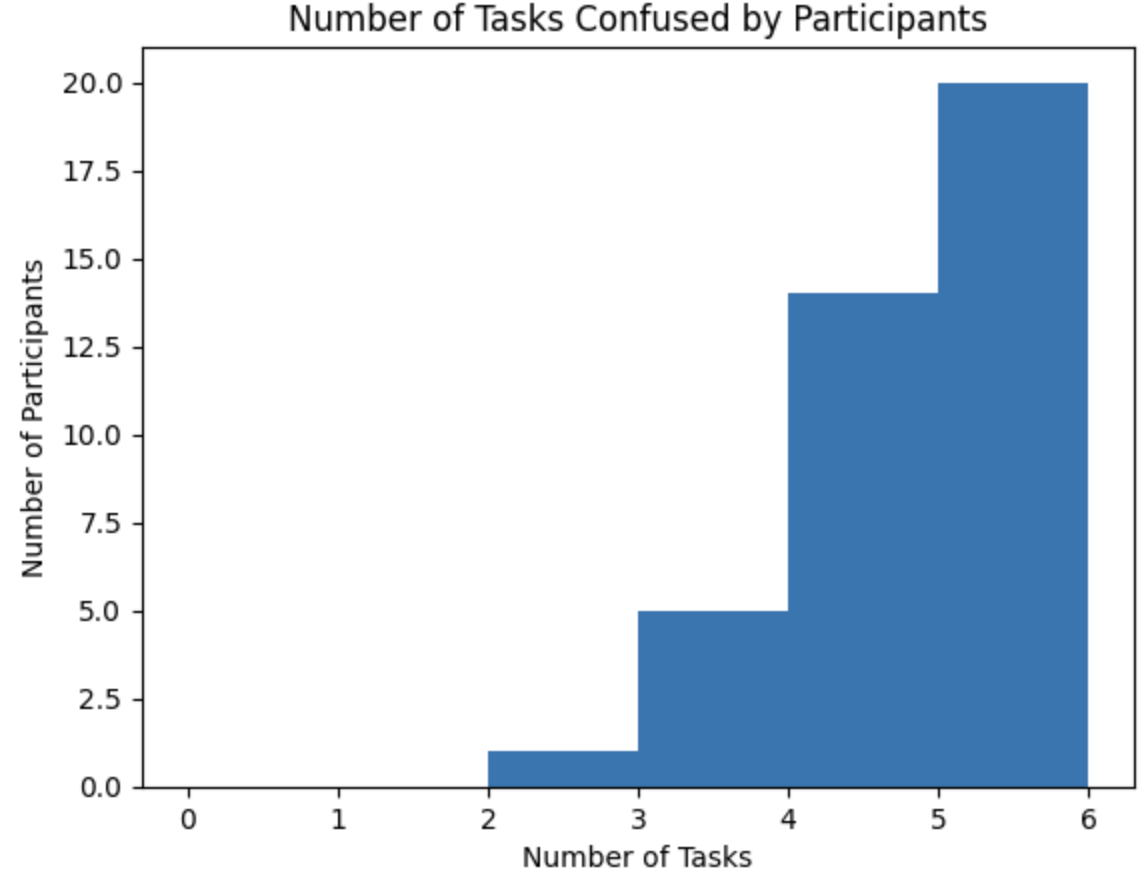
Number of Tasks Confused by Participants: This bar chart shows that the majority of participants were confused by five or six tasks, suggesting that the tasks presented significant cognitive challenges.
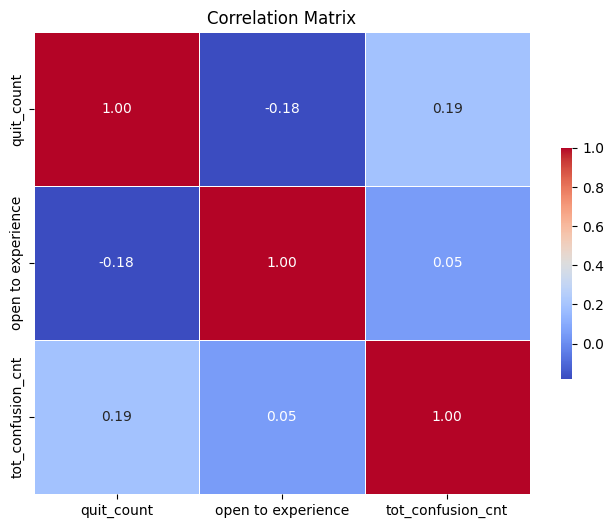
Correlation Matrix: The correlation matrix illustrates the relationships between key variables: quit count, openness to experience, and total confusion count. For example, there is a positive correlation (0.19) between quit count and confusion, suggesting that higher confusion may lead to higher quitting.
Pilot data analysis
Over the piloting period, 103 groups of data were collected by 7 researchers across 3 months. Both qualitative and quantitative data analysis were performed.
Based on affection:



Spearman’s correlation
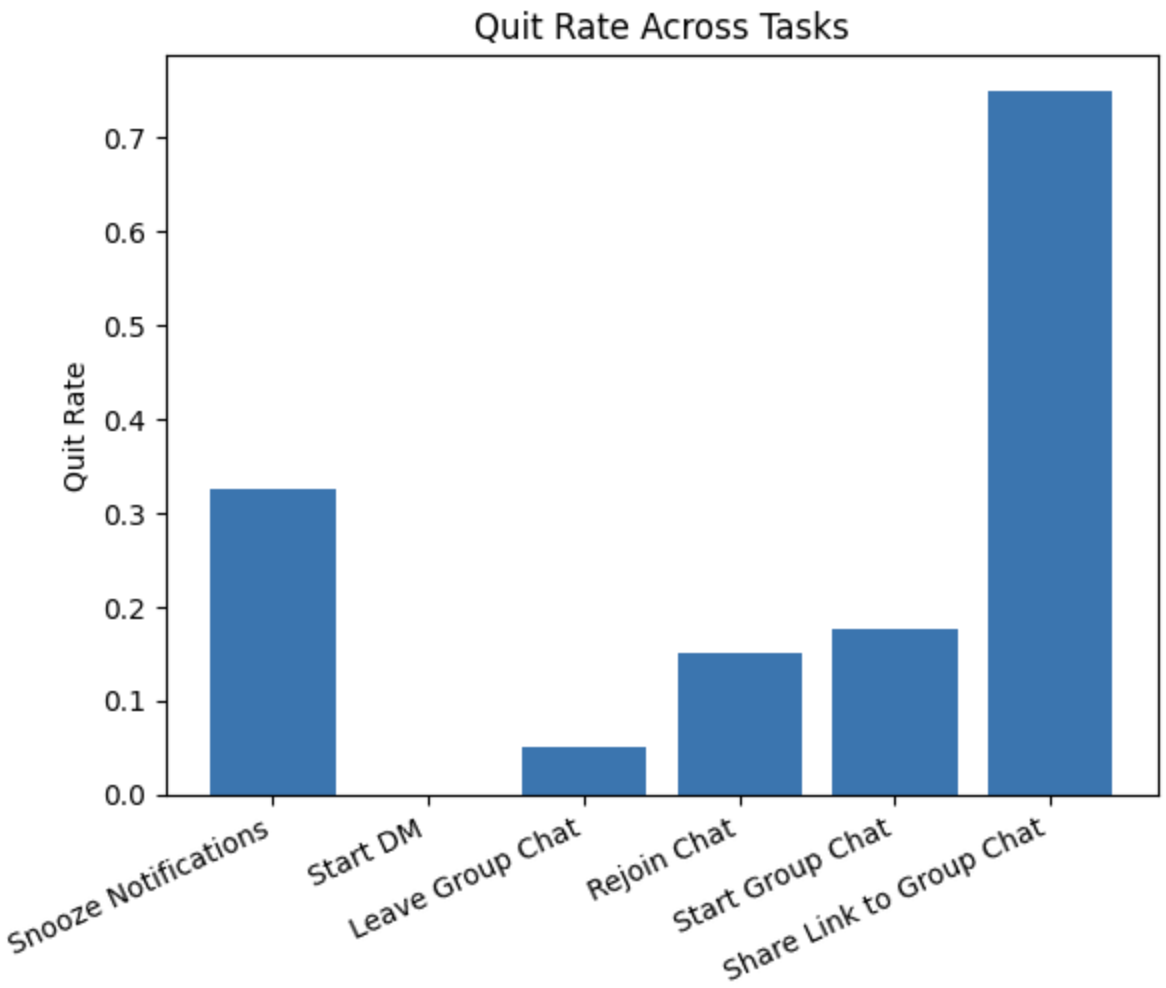
Quit Rate Across Tasks: The task "Share Link to Group Chat" had the highest quit rate, suggesting it was particularly difficult or confusing for users, while tasks like "Start DM" had much lower quit rates.

Average Ease Rating and Scaled Quit Rate by Task: This combined bar chart visualizes the average ease rating and the quit rate (scaled) for each task. It shows a clear inverse relationship between ease of use and quit rate—tasks with higher ease ratings, such as "Snooze Notifications," tend to have lower quit rates, while tasks like "Share Link to Group Chat" have lower ease ratings.
Insights and recommendations
Based on the findings from this UX research study, several key insights and recommendations emerge:
Validation for frustrating features
The data indicates that a majority of participants experienced confusion during at least five or six tasks. This suggests that the overall cognitive load of the tasks may have been too high. To improve user experience, it is essential to simplify complex workflows, especially for tasks like "Share Link to Group Chat," which had both the highest confusion and quit rates.
Enhance Usability for High-Quit-Rate Tasks
The strong correlation between ease-of-use ratings and quit rates reinforces the need for usability improvements in tasks with high quit rates. For example, the "Share Link to Group Chat" task had the lowest ease-of-use score and the highest quit rate. This suggests a critical need to rework the design of this task to ensure it is more intuitive and accessible for users.
Consider User Personality Traits in Design
The slight negative correlation between "openness to experience" and "quit rate" suggests that personality traits may influence how users interact with certain features. Users who are more open to new experiences are less likely to quit, even when faced with challenges. This insight could be used to personalize user experiences. Designers can offer more adaptive features or support mechanisms based on user personality.
Optimize Task Order to Reduce Learning Effects
The findings from the order effect analysis suggest that certain task orders can reduce learning effects, which may skew the results of subsequent tasks. In future designs, it is recommended to strategically order tasks to minimize this bias. This will ensure that each task is assessed independently and will lead to more accurate data collection on task-specific difficulties.
Further Review of Binary Variables
Variables such as "Surprise (+)" and "Surprise (-)" showed only slight agreement in coding, suggesting ambiguity in their interpretation. Future studies should consider simplifying or clarifying the definitions of these binary variables to improve coding accuracy and consistency between raters. This could involve refining the codebook or providing additional training for raters before data collection begins.
Results:
The 5 big categories of response contents were centered on: frustration, familiarity, insights, verbalization, and motivation. Frustration, being the largest category, contains contents in both explanations for actions and verbal complaints.
Negative emotions were reported the most among positive, neutral, and negative responses. Negative responses (57.3%) was more than half.
Based on categories of responses and affective states, we decided to code user behavior & verbal responses by their affection, navigation behavior, and insights provided.
Process:
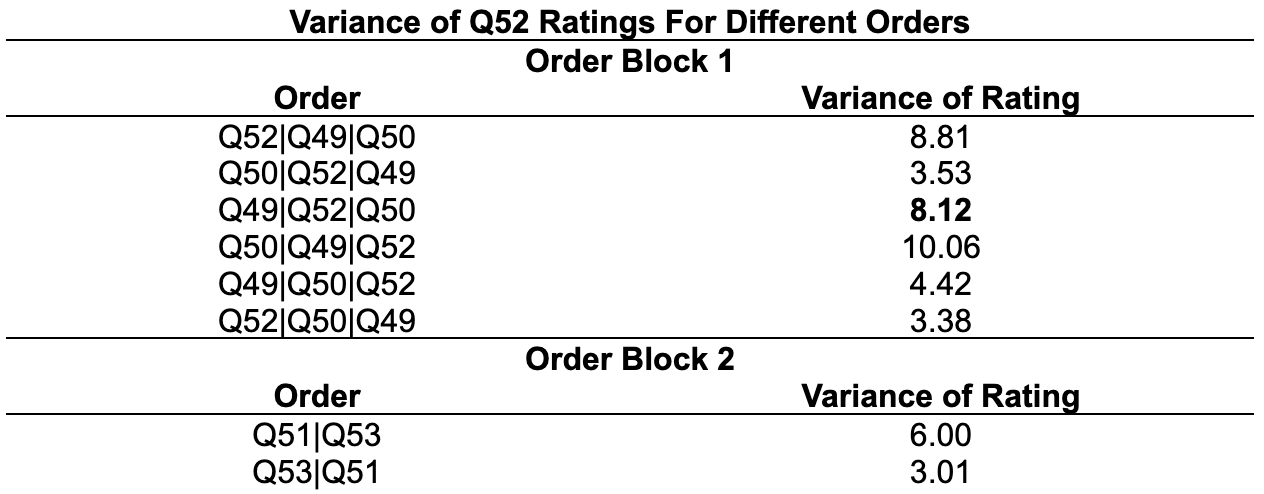
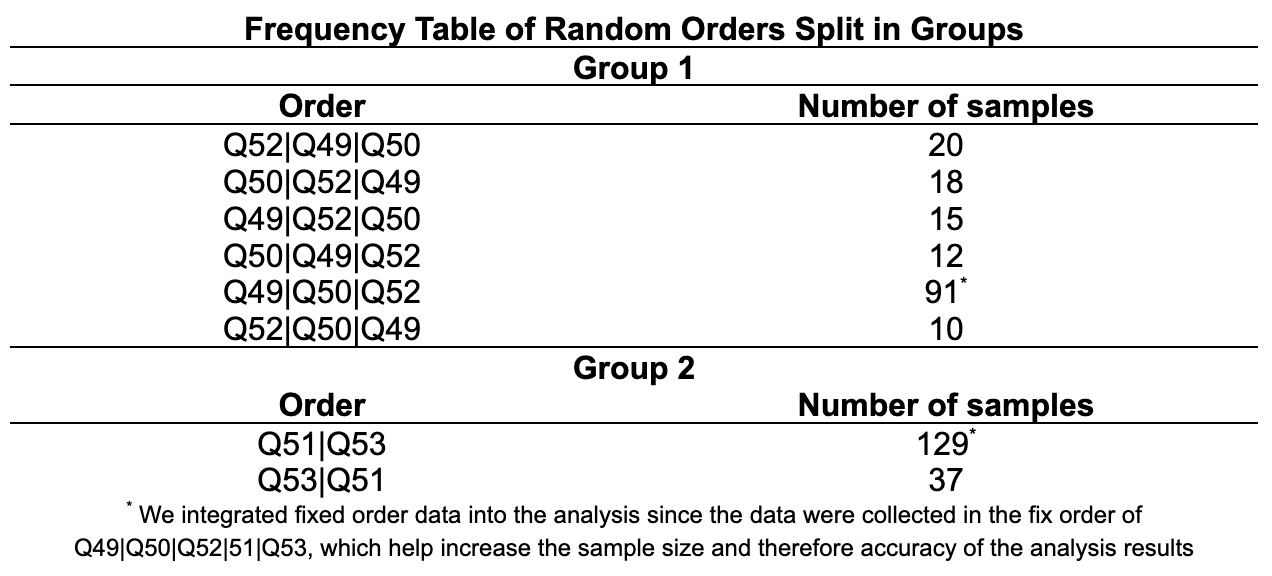
1. We split the investigation into two parts. The first part is evaluating the independence of order and learning/ratings among the first group of questions that were randomized together (Q49, Q50, Q52). The second part is evaluating that among the other two questions that were randomized together (Q51, Q53).
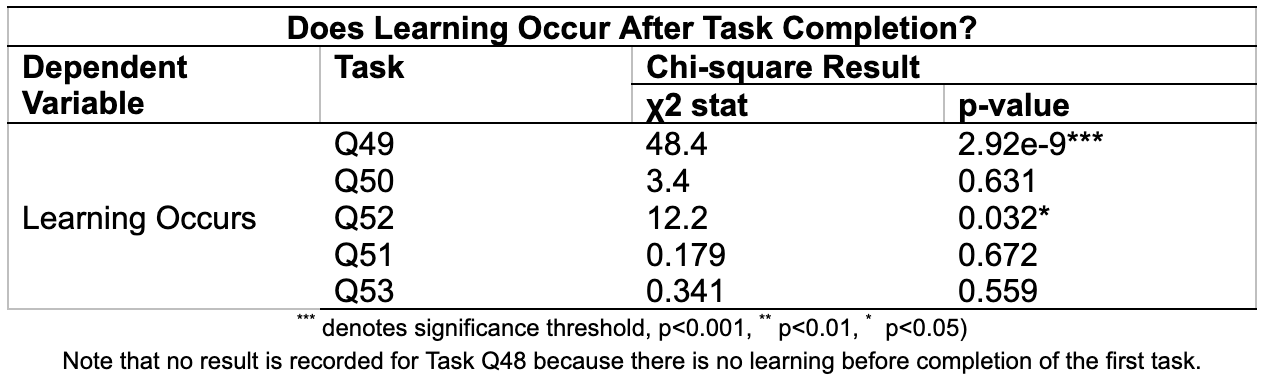
2. We conducted chi-square tests to explore whether dependency exists between task order and learning rates and Levene’s test to check for equal variance across tasks for each of the two random order blocks. The results of chi-square test and Levene’s tests are shown in Table 3 and 4.
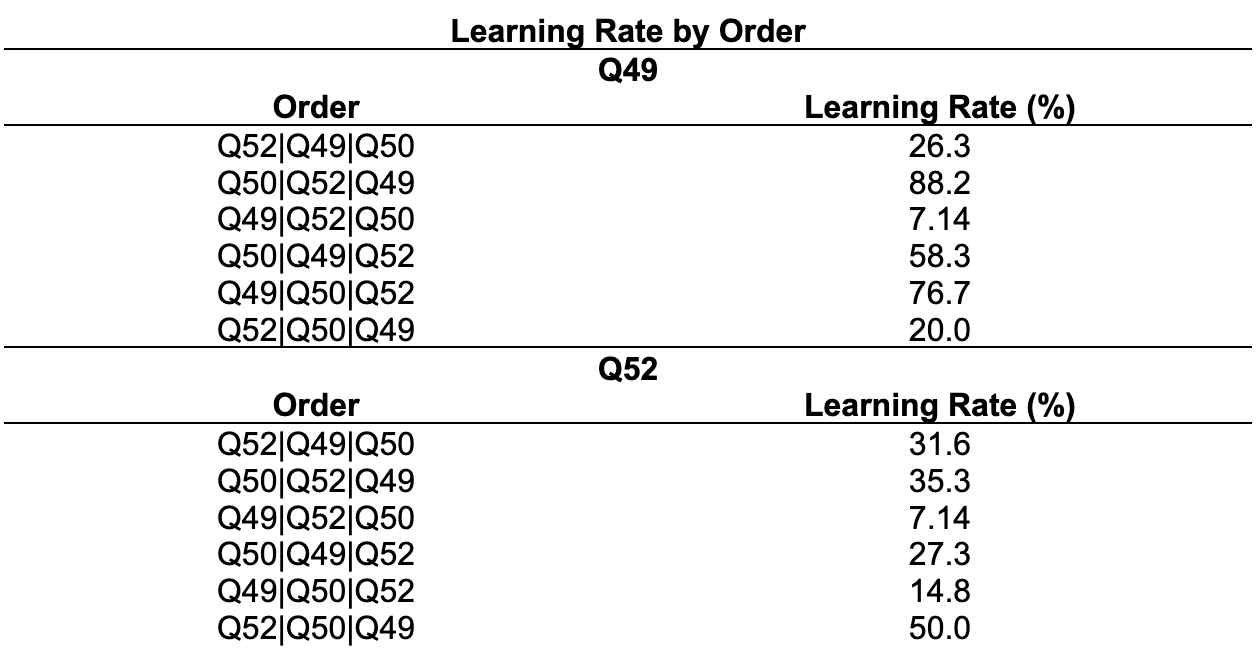
3. We found that Q49 and Q52 has significance difference in learning for different task orders. We compared across the mean learning rate across different task orders for Q49 and Q52. In both cases, learning is most reduced for task order Q49|Q52|Q50, as shown in. Table 5. Therefore, in order to minimize learning rate for those two tasks, we select order Q49|Q52|Q50 in sequent experiment.
4. Using Levene’s tests, we found that the variance of Q52 ratings differs across different orders for both random blocks. We then compared the variance of Q52 ratings for the different order blocks.
Conclusion:
Order Q50|Q49|Q52 has the highest rating variance among the first order block and Q51|Q53 the second order block. However, because we prioritize learning rate reduction. We choose Q49|Q52|Q50 over Q50|Q49|Q52, which gives 3rd highest rating variance for Q52. Our final optimal experiment order is thus Q49|Q52|Q50|Q51|Q53.
The order of the tasks by their code is therefore: "SN", "DM", "RC", "LC", "SC", "SL".
Official Study
Official Data Collection
Each round of data collection section was about 30 minutes. The study was conducted through zoom. Participants went to our Figma prototype to perform the tasks. They were required to share their screen and open their camera while they complete the tasks. Researchers logged any unusual behaviors and recorded the whole data collection process.
All of us followed a discussion guide that standardized the collection process to minimize possible confounding variables brought by wording or researcher personality.
Sample session
Official Data Analysis
Part 1. Mixed method analysis (qualitative + quantitative)
Data collection guide

Part 2. Quantitative Analysis
Rationale: Our quantitative data analysis was mainly centered on eliminating possible confounding variables for this experiment design. Specifically, we have performed data analysis on whether order of tasks influence user ratings and frustration levels.
During the piloting period, some ordering of tasks increased exploration of the prototype to an extent that ratings of subsequent tasks may not accurate – rated less frustrated or easier. Participants may have looked through all of the prototype for some tasks and as such have found the answers to subsequent tasks during that exploration. Therefore, those subsequent tasks may not be rated accurately for ease or frustration.
Therefore, the goal of the analysis is to determine the best order of tasks, defined as one that minimizes the learning from one task to the next as a main concern and ideally also maximizes variation of ratings across all tasks. To determine whether a best order exists, we evaluated the independence between the orders and each of learning and ratings using chi-square tests.